by Stephanie Dunn
February 26, 2016
Resources on servers and network devices can change over time due to the addition of new services or increased user demands. Attacks can overwhelm network resources and result in degraded network performance, down public facing websites, and disrupt vital services for an organization. This dashboard aligns with the NIST Cybersecurity Framework (CSF) PR.DS-4 subcategory, which can assist the organization by monitoring resources across network assets, ensuring that availability is maintained.
The CSF provides guidance based on existing standards, guidelines, and practices that can be tailored to specific organizational needs. This dashboard utilizes the Data Security subcategory within the CSF Protect function, which assists in protecting the confidentiality, integrity, and availability of data within an organization.
Organizations are not immune to attacks against network servers and devices. Most network attacks are designed to overwhelm resources on a server that can result in long-term service disruptions or outages. This dashboard can assist the organization in monitoring system resource changes, detecting event spikes, and high utilization events on servers and other devices. System resource changes can include spikes with CPU usage, memory utilization, network throughput and I/O operations. Several components will detect anomalies within both inbound and outbound network connections. This could indicate the presence of newly installed applications, or possible attacks that could overwhelm network resources. Network devices such as routers, firewalls, and other appliances detect high utilization events, which can allow the analyst to correlate events to a specific device. Every public facing network asset plays a vital role in ensuring business continuity and availability of resources. By utilizing this dashboard, organizations can effectively monitor resources on network assets, which can aid in ensuring performance and availability of services across the enterprise.
By utilizing the Log Correlation Engine (LCE), network resources can be easily monitored through Tenable.sc Continuous View (SC CV). The LCE utilizes the System Monitor TASL script, which includes default levels for global alerting. By default, this script will generate a new alert any time CPU usage exceeds more than 90%, memory usage of more than 90%, or disk usage of more than 90% has been encountered or a load level larger than 3. The analyst can modify settings by editing a file named “system_monitor.conf” in the local LCE plugins directory. More information can be found within the Log Correlation Engine documentation on Tenable’s support portal.
The dashboard and its components are available in the Tenable.sc Feed, a comprehensive collection of dashboards, reports, Assurance Report Cards, and assets. The dashboard can be easily located in the Tenable.sc Feed under the category Compliance & Configuration Assessment. The dashboard requirements are:
- Tenable.sc 5.2.0
- LCE 6.0.0
- NNM 5.9.0
- NetFlow EventData
Tenable.sc Continuous View (Tenable.sc CV) is the market-defining continuous network monitoring platform. Tenable.sc CV includes active vulnerability detection with Nessus, passive vulnerability detection with Nessus Network Monitor (NNM), and log correlation with Log Correlation Engine (LCE). Using Tenable.sc CV, an organization will obtain the most comprehensive and integrated view of its network. LCE provides deep packet inspection to continuously discover changes on network resources.
This dashboard contains the following components:
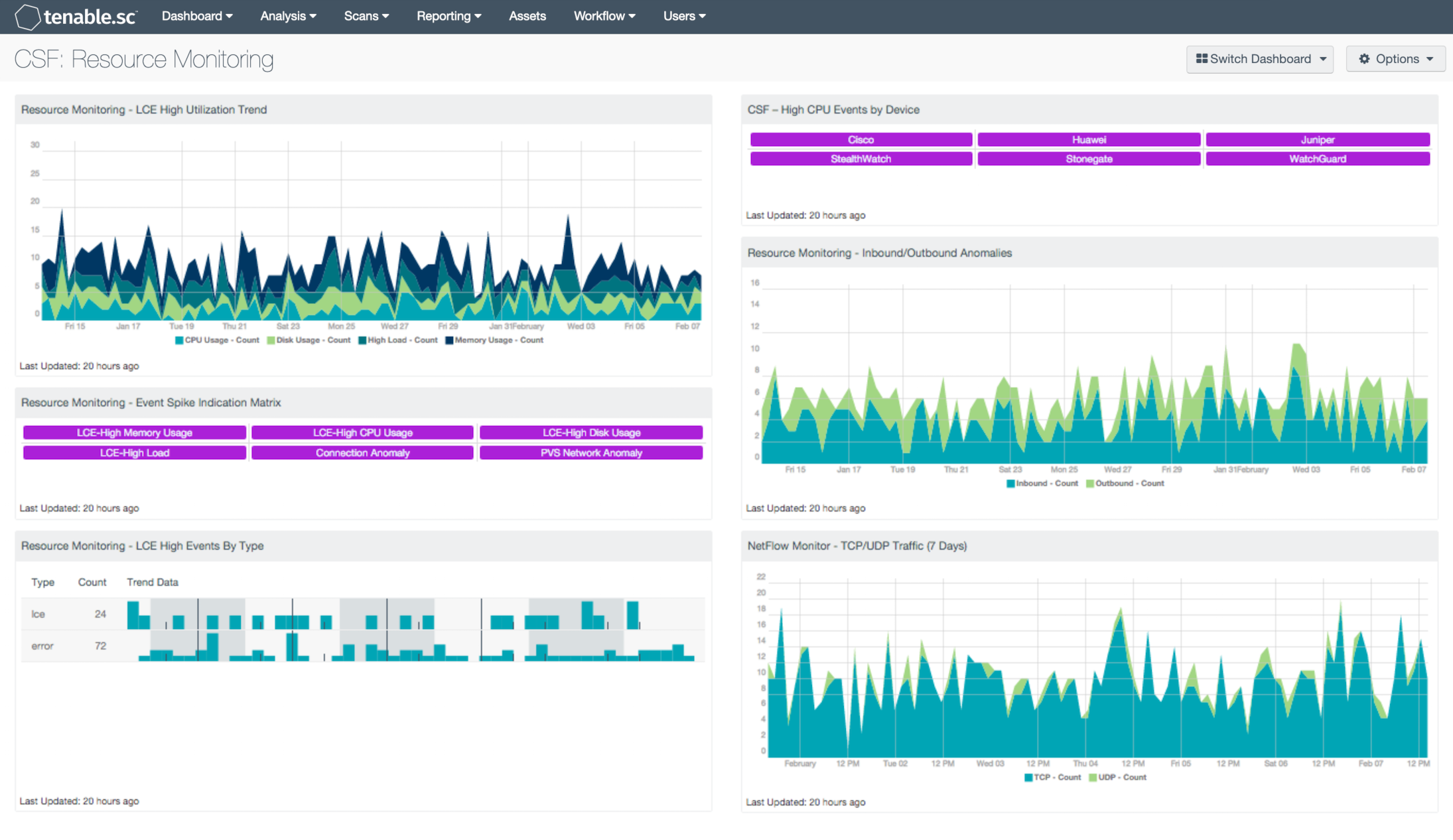
- Resource Monitoring – LCE High Utilization Trend: This chart trends high utilization events found within the environment for the most common targets: CPU cycles, RAM utilization, network throughput and I/O operations. Results are displayed to the analyst in an easy to understand graph covering the previous 25 days. Positioning the mouse cursor along the trend presents a pop-up indication that contains the date/time and event count.
- Resource Monitoring – Event Spike Indication Matrix: This matrix component provides indication for event spikes found within the environment for the most common targets: CPU cycles, RAM utilization, network throughput and I/O operations. Triggered events are displayed to the analyst in an easy to understand indicator matrix covering the previous 72 hours. An indicator that is highlighted purple represents that a spike event is present for during the designated time period.
- Resource Monitoring – LCE High Events by Type: This table component displays high utilization events found within the environment by type. Results are displayed to the analyst in an easy to understand table covering the previous 72 hours. This allows the analyst to correlate high utilization events to specific event types, such as errors. High utilization events that are all of a specific type could indicate potential areas of concern within the environment.
- CSF – High CPU Events by Device: This component presents information on high CPU or high traffic based events on network devices. The matrix presents activity indicators for various network devices such as firewalls, routers, and other network devices over the last 72 hours. This component assumes that if log events were received from a particular device, then that device is active on the network. Once an event is detected, the indicator will turn purple. The analyst should review events to determine if further action is needed.
- Resource Monitoring – Inbound/Outbound Anomalies: This chart trends inbound and outbound connection anomalies found within the environment. Results are displayed to the analyst in an easy to understand graph covering the previous 25 days. Positioning the mouse cursor along the trend presents a pop-up indication, which contains the date/time and count.
- NetFlow Monitor – TCP/UDP Traffic (7 Days): This component presents the analyst with a graphical representation and trending for TCP vs. UDP over the specified timeframe. This provides a fast method to conduct visual trend analysis of specific protocols.